Chapitre 1 - Introduction à PyTorch et Optimisation de Modèles (partie 1)
🎯 Objectifs du Chapitre
À la fin de ce chapitre, vous saurez :
- Créer et manipuler des tenseurs PyTorch sur CPU et GPU.
- Calculer automatiquement les gradients à l’aide de
autograd. - Définir une fonction de perte.
- Utiliser un optimiseur pour ajuster les paramètres d’un modèle.
- Implémenter une boucle d'entraînement simple.
📖 1. Qu'est-ce que PyTorch ?
PyTorch est une bibliothèque Python de machine learning open-source développée par Facebook (FAIR). Elle est conçue pour faciliter la création et l'entraînement de modèles, en particulier dans le domaine du deep learning.
Elle repose principalement sur deux éléments :
A) Les tenseurs, des structures de données similaires aux tableaux NumPy (ndarray), mais avec des fonctionnalités supplémentaires pour :
- le calcul différentiel automatique,
- l'accélération GPU,
- l’entraînement de réseaux de neurones.
B) Le module autograd permet de calculer automatiquement les gradients nécessaires à l'entraînement des modèles, en suivant toutes les opérations effectuées sur les tenseurs.
D'autres bibliothèques Python similaires existent, comme :
- TensorFlow : développé par Google, très utilisé pour des déploiements à grande échelle.
- Keras : interface haut niveau de TensorFlow, plus simple mais moins flexible.
- JAX : plus récent, optimisé pour la recherche et les calculs scientifiques à haute performance.
Dans le cadre de ce cours, nous utiliserons PyTorch car :
- elle est largement adoptée par la communauté de la recherche en deep learning,
- elle est plus lisible et plus facile à déboguer que TensorFlow et JAX,
- elle offre plus de possibilités que Keras,
- elle est bien documentée et est l'une des bibliothèques les plus utilisées en science des données (Data Science en anglais) et en apprentissage machine (Machine Learning en anglais).
📖 2. Qu'est-ce qu'un tenseur ?
Les tenseurs sont la structure de base de PyTorch. Ce sont des tableaux multidimensionnels similaires aux ndarray de NumPy, mais avec des fonctionnalités supplémentaires pour le GPU et le calcul automatique des gradients. Un tenseur est une structure de données qui généralise les matrices à un nombre quelconque de dimensions:
- Un scalaire est un tenseur 0D.
- Un vecteur est un tenseur 1D.
- Une matrice est un tenseur 2D.
- On peut avoir des tenseurs 3D, 4D, etc.
Les tenseurs à haute dimension sont très utilisés en deep learning (par exemple pour les images ou les vidéos). Nous allons voir comment créer et manipuler des tenseurs dans PyTorch. Pour utiliser les fonctions de PyTorch, il faut d'abord l'importer :
import torchVous devez copier-coller les exemples de code ci-dessous dans un notebook Jupyter pour les tester et voir les affichages.
📖 3. Création de tenseurs
Il existe plusieurs manières de créer un tenseur en PyTorch.
3.1. À partir de données Python (listes ou tuples)
# Depuis une liste
a = torch.tensor([1, 2, 3])
print(a)
# Depuis une liste de listes (matrice)
b = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(b)
# On peut aussi spécifier le type de données
c = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float32)
print(c, c.dtype)3.2. Avec des fonctions de construction
# Tenseur rempli de zéros
z = torch.zeros(2, 3)
print(z)
# Tenseur rempli de uns
o = torch.ones(2, 3)
print(o)
# Tenseur vide (valeurs non initialisées)
e = torch.empty(2, 3)
print(e)
# Identité (matrice diagonale)
eye = torch.eye(3)
print(eye)3.3. Avec des suites régulières
PyTorch permet de générer facilement des suites de nombres avec des pas réguliers. Deux fonctions sont particulièrement utiles :
- torch.arange(debut, fin, pas)
- Crée une suite en commençant à
debut - S’arrête avant
fin(attention, la borne supérieure est exclue !) - Utilise le
pasindiqué
# De 0 à 8 inclus, avec un pas de 2
r = torch.arange(0, 10, 2)
print("torch.arange(0, 10, 2) :", r)
# De 5 à 20 exclu, avec un pas de 3
r2 = torch.arange(5, 20, 3)
print("torch.arange(5, 20, 3) :", r2)
# ⚠️ Remarque : la borne supérieure (ici 10 ou 20) n'est jamais incluse- torch.linspace(debut, fin, steps)
- Crée une suite de
stepsvaleurs régulièrement espacées - Inclut à la fois
debutetfin
# 5 valeurs entre 0 et 1 inclus
l = torch.linspace(0, 1, steps=5)
print("torch.linspace(0, 1, steps=5) :", l)
# 4 valeurs entre -1 et 1 inclus
l2 = torch.linspace(-1, 1, steps=4)
print("torch.linspace(-1, 1, steps=4) :", l2)Résumé des différences
arange→ on fixe le pas entre les valeurs, la fin est exclue.linspace→ on fixe le nombre de valeurs, la fin est incluse.
Exemple comparatif :
print(torch.arange(0, 1, 0.25)) # [0.00, 0.25, 0.50, 0.75]
print(torch.linspace(0, 1, 5)) # [0.00, 0.25, 0.50, 0.75, 1.00]3.4. Avec des nombres aléatoires
# Attention dans les exemples suivants, les crochets [] veulent dire que la valeur de la borne est incluse, contrairement à aux parenthèses () qui signifient que la borne est exclue.
# Uniforme entre [0, 1)
u = torch.rand(2, 2)
print("Uniforme [0,1) :\n", u)
# Distribution normale (moyenne=0, écart-type=1)
n = torch.randn(2, 2)
print("Normale standard (0,1) :\n", n)
# Distribution normale avec moyenne (mean) et écart-type (std) choisis
custom = torch.normal(mean=2.0, std=3.0, size=(2,2))
print("Normale (moyenne=10, écart-type=2) :\n", custom)
# Fixer la graine pour la reproductibilité
torch.manual_seed(42)
print("Reproductibilité :\n", torch.rand(2, 2)) # toujours le même résultat📖 4. Connaître la forme d'un tenseur
Un tenseur peut avoir n’importe quelle dimension. La méthode .shape permet de connaître sa taille.
# Scalaire (0D)
s = torch.tensor(5)
print("Scalaire :", s, "shape =", s.shape)
# Vecteur (1D)
v = torch.tensor([1, 2, 3, 4])
print("Vecteur :", v, "shape =", v.shape)
# Matrice (2D)
m = torch.tensor([[1, 2, 3], [4, 5, 6]])
print("Matrice :\n", m, "shape =", m.shape)
# Tenseur 3D (par exemple, 2 matrices de taille 3x3)
t3 = torch.zeros(2, 3, 3)
print("Tenseur 3D shape =", t3.shape)
# Tenseur 4D (par exemple, un mini-batch de 10 images RGB de 32x32)
t4 = torch.zeros(10, 3, 32, 32)
print("Tenseur 4D shape =", t4.shape)📖 5. Types de tenseurs et conversion
- Vous pouvez spécifier le type de données (
dtype) lors de la création :
x = torch.tensor([1.2, 3.4, 5.6])
print(x.dtype) # float32 par défaut
x_int = x.to(torch.int32)
print(x_int, x_int.dtype)
x_float64 = x.double()
print(x_float64, x_float64.dtype)- Conversion d’un tenseur existant :
x_int = x.to(torch.int32)
print(x_int.dtype)📖 6. Opérations de base
PyTorch supporte de nombreuses opérations sur les tenseurs :
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
# Addition
print(a + b)
# Multiplication élément par élément
print(a * b)
# Produit matriciel
mat1 = torch.rand(2, 3)
mat2 = torch.rand(3, 4)
print(torch.mm(mat1, mat2))📖 7. Tenseurs sur GPU
Pour profiter de l’accélération GPU, il suffit de déplacer un tenseur sur le device CUDA. Pour cela, on a 3 options :
7.1. Placer un tenseur directement sur le GPU lors de sa création
if torch.cuda.is_available():
device = torch.device("cuda")
tenseur_gpu = torch.zeros(2, 3, device=device)
print("Tenseur sur GPU :", tenseur_gpu)
else:
print("Pas de GPU disponible, utilisation du CPU.")7.2. Déplacer un tenseur existant sur le GPU avec .to(device)
if torch.cuda.is_available():
device = torch.device("cuda")
x_gpu = x.to(device)
print("Tenseur sur GPU :", x_gpu)
else:
print("Pas de GPU disponible, utilisation du CPU.")7.3. Forcer la création de tous les tenseurs sur le GPU
if torch.cuda.is_available():
device = torch.device("cuda")
torch.set_default_device(device)
x_defaut_gpu = torch.zeros(2, 3) # sera créé sur le GPU par défaut
print("Tenseur par défaut sur GPU :", x_defaut_gpu)
else:
print("Pas de GPU disponible, utilisation du CPU.")📖 8. Manipulation avancée des tenseurs
Une fois créés, les tenseurs peuvent être transformés et réarrangés. PyTorch fournit de nombreuses fonctions pour modifier leur forme, leurs dimensions ou leur ordre.
8.1. Changer la forme avec view et reshape
view: retourne un nouveau tenseur qui partage la même mémoire que l’original. Cela implique que le tenseur soit contigu. Un tenseur est dit contigu lorsque ses données sont stockées de manière consécutive en mémoire, c’est-à-dire que PyTorch peut lire tous les éléments dans l’ordre sans sauts. Certaines opérations, comme la transposition (t()), rendent le tenseur non contigu, et dans ce casviewéchoue.reshape: similaire àview, mais plus flexible car il tente d’utiliser la mémoire existante, mais crée une copie si nécessaire.reshapefonctionne dans tous les cas de figures.
x = torch.arange(12) # tenseur 1D [0, 1, ..., 11]
print("x :", x)
# Transformer en matrice 3x4
x_view = x.view(3, 4)
print("view en 3x4 :\n", x_view)
# Transformer en matrice 2x6
x_reshape = x.reshape(2, 6)
print("reshape en 2x6 :\n", x_reshape)Autre exemple pour illustrer la différence entre view et reshape :
# Création d'un tenseur 2x3
x = torch.arange(6).view(2, 3)
print("x :\n", x)
print("Contigu :", x.is_contiguous())
# Transposition → rend le tenseur non contigu
y = x.t()
print("\ny (transposé) :\n", y)
print("Contigu :", y.is_contiguous())
# view échoue sur un tenseur non contigu
try:
z = y.view(6)
except Exception as e:
print("\nErreur avec view :", e)
# reshape fonctionne toujours
z2 = y.reshape(6)
print("\nreshape fonctionne :", z2)8.2. Changer l’ordre des dimensions : permute
permuteréarrange les dimensions dans un nouvel ordre.- Très utile pour manipuler les données d’images ou de séquences.
# Exemple avec un tenseur 3D (batch, hauteur, largeur)
t = torch.randn(2, 3, 4) # forme (2, 3, 4)
print("Tenseur original :", t.shape)
# Inverser l'ordre (largeur, hauteur, batch)
p = t.permute(2, 1, 0)
print("Après permute :", p.shape)8.3. Ajouter ou supprimer des dimensions : unsqueeze et squeeze
unsqueeze(dim): ajoute une dimension de taille 1 à la positiondim.squeeze(): supprime toutes les dimensions de taille 1.
v = torch.tensor([1, 2, 3])
print("Forme initiale :", v.shape)
v_unsq = v.unsqueeze(0) # ajoute une dimension au début
print("Après unsqueeze(0) :", v_unsq.shape)
v_sq = v_unsq.squeeze() # supprime les dimensions de taille 1
print("Après squeeze() :", v_sq.shape)8.4. Concaténer ou empiler des tenseurs
torch.cat: concatène le long d’une dimension existante.torch.stack: empile en ajoutant une nouvelle dimension.
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
cat = torch.cat((a, b), dim=0)
print("torch.cat :", cat)
stack = torch.stack((a, b), dim=0)
print("torch.stack :", stack)
print("Forme de stack :", stack.shape)📖 9. Autograd avec PyTorch
En Deep Learning, nous travaillons souvent avec des fonctions compliquées dépendant de plusieurs variables. Pour entraîner un modèle, nous avons besoin de calculer automatiquement les dérivées de ces fonctions. C'est là qu'intervient Autograd qui est le moteur de différentiation automatique de PyTorch.
9.1. Création d'un tenseur suivi
Pour qu'un tenseur suive les opérations et calcule les gradients automatiquement, il faut définir requires_grad=True :
x = torch.tensor([2.0, 3.0], requires_grad=True)
print(x)Ici, x est un tenseur avec suivi des gradients. Toutes les opérations futures sur ce tenseur seront enregistrées pour pouvoir calculer les dérivées automatiquement.
9.2. Opérations sur les tenseurs
Toutes les opérations effectuées sur ce tenseur sont automatiquement enregistrées dans un graphe computationnel dynamique.
y = x ** 2 + 3 * x # y = [y1, y2]
print(y)Dans ce cas :
xest la variable d'entrée.yest calculé à partir dexavec les opérationsx**2et3*x.
Chaque opération devient un nœud du graphe et PyTorch garde la trace des dépendances pour pouvoir calculer les gradients.
📖 10. Graphe computationnel
Un graphe computationnel est une structure qui représente toutes les opérations effectuées sur les tenseurs. Chaque nœud du graphe correspond à un tenseur ou à une opération mathématique, et les arêtes indiquent les dépendances entre eux.
10.1. torchviz
Pour visualiser le graphe dans PyTorch, on peut utiliser torchviz (qu'il faudra installer avec pip install torchviz) :
from torchviz import make_dot
z = y.sum()
make_dot(z, params={'x': x})Cela produira une image avec des nœuds pour chaque opération et des flèches indiquant les dépendances :
- Les nœuds \(x^2\) et \(3x\) représentent les opérations effectuées sur \(x\).
- Le nœud \(y\) combine ces deux résultats.
- Le graphe permet à PyTorch de savoir quelles dérivées calculer et dans quel ordre.
10.2. Note sur le graphe généré par PyTorch
Quand on visualise le graphe interne avec un outil comme torchviz :
- Le bloc jaune avec () correspond au tenseur final (ici
z). - Les blocs intermédiaires (
PowBackward0,AddBackward0, etc.) représentent les opérations qui seront différentiées telles quePowBackward0est l'opération inverse associée àx**2,MulBackward0celle associée à3*x,
AddBackward0combine les deux résultats et représenteyet enfinSumBackward0correspond auy.sum()qui est égal àz. - Le bloc
AccumulateGradcorrespond à l’endroit où le gradient est stocké dans la variable d’entrée (icix.grad).
📖 11. Calcul des gradients et rétropropagation
Autograd utilise ce graphe pour calculer automatiquement les dérivées par rapport à x, en utilisant la méthode backward() :
z = y.sum() # z = y1 + y2
z.backward()
print(x.grad)backward()calcule les dérivées dezpar rapport à chaque élément dex.x.gradcontient maintenant les gradients.
11.1. But de la rétropropagation
Le but est de minimiser une fonction de perte en ajustant les paramètres du modèle. La rétropropagation permet de calculer efficacement les gradients nécessaires pour mettre à jour ces paramètres via des algorithmes d'optimisation comme la descente de gradient.
Le gradient d’une fonction \(f(x)\) est la pente de la courbe en un point. Le gradient indique la direction de variation la plus forte de la fonction : c’est comme une boussole qui pointe vers la direction où la fonction croît le plus vite. Pour minimiser la perte, on avance dans la direction opposée. Voici comment on calcule le gradient :
- En 1D : \(f'(x) = \lim_{h \to 0} \frac{f(x+h) - f(x)}{h}\)
- En plusieurs dimensions : \(\nabla f(x) = \left( \frac{\partial f}{\partial x_1}, \dots, \frac{\partial f}{\partial x_n} \right)\)
Par exemple si \(f(x) = x^2\) alors :
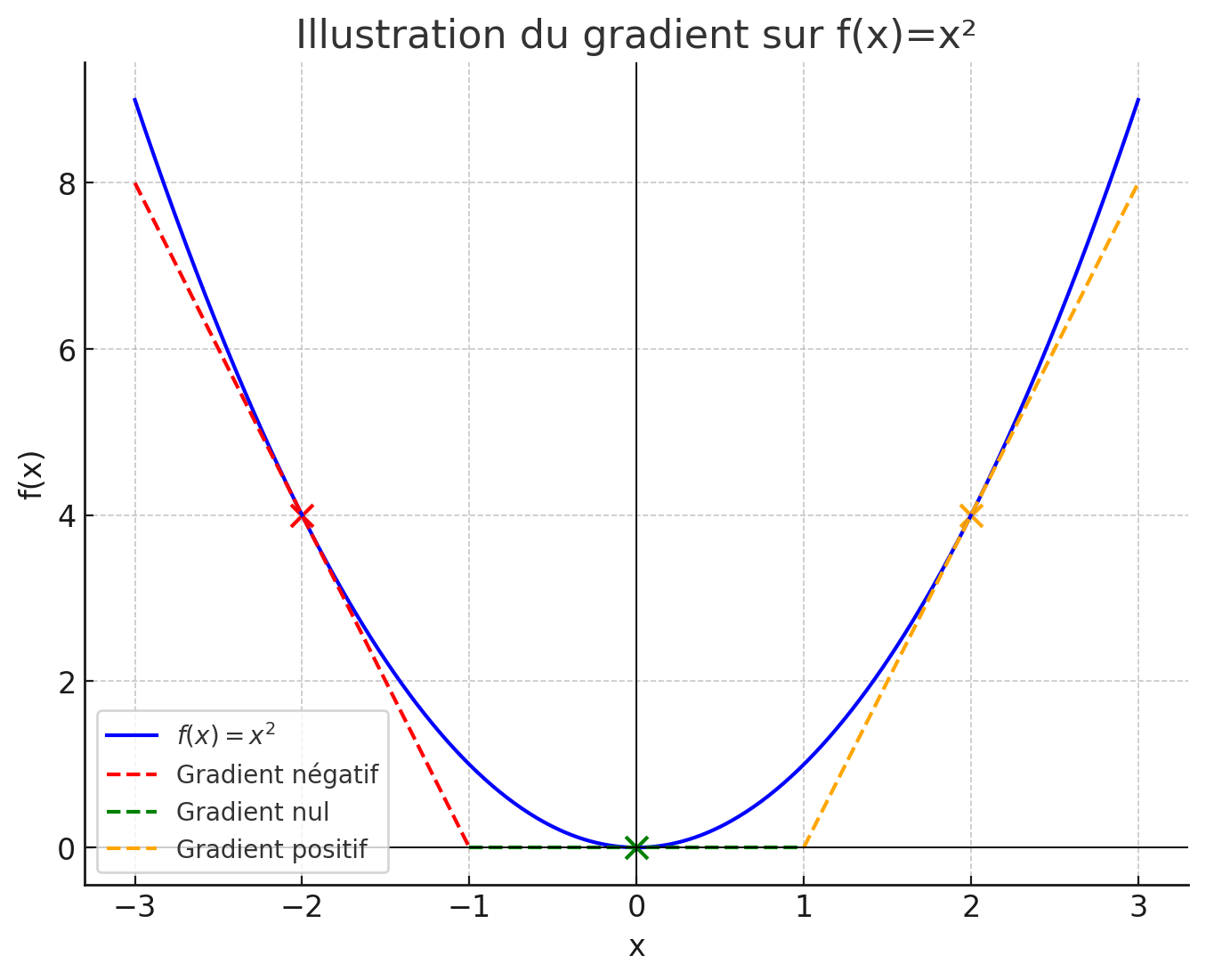
- Pour \( x < 0 \), gradient négatif → la fonction décroît.
- Pour \( x > 0 \), gradient positif → la fonction croît.
- Au minimum (en \( x=0 \)), gradient nul.
Pour minimiser la fonction de perte, il faut trouver \(x\) pour lequel \(\nabla f(x) = 0\).
Attention : un gradient nul peut aussi correspondre à un maximum. En apprentissage, on espère converger vers un minimum.
11.2. Principe de la rétropropagation
Le principe de la rétropropagation signifie que PyTorch parcourt le graphe en sens inverse pour faire le calcul des dérivées. Si on repart sur l'exemple de la section précédente, la rétropropagation dans PyTorch :
- Commence par la sortie
z. - Recule vers les nœuds précédents (
ypuisx) en appliquant la règle de dérivation. - Stocke le gradient dans
x.grad.
11.3. Calcul des gradients dans notre exemple
- \(\frac{dz}{dy} = 1\) car \(z = y.sum()\)
- \(\frac{dy}{dx} =\) dérivée de \((x^2 + 3*x) = 2*x + 3\)
- \(\frac{dz}{dx} = \frac{dz}{dy} * \frac{dy}{dx} = 2*x + 3\)
On obtient donc :
print(x.grad) # tensor([7., 9.])11.4. Détail du calcul des gradients
On a \(y = [y_1, y_2] = [x_1² + 3x_1, x_2² + 3x_2]\) et \(z = y_1 + y_2\).
Étape 1 : dérivée de z par rapport à y
Comme \(z = y_1 + y_2\), on a \(\frac{dz}{dy_1} = 1\) et \(\frac{dz}{dy_2} = 1\).
On peut regrouper sous forme vectorielle, telle que \(\frac{dz}{dy} = [\frac{dz}{dy_1}, \frac{dz}{dy_2}] = [1, 1]\).
Étape 2 : dérivée de y par rapport à x
On a \(\frac{dy_1}{dx_1} = 2x_1 + 3\) et \(\frac{dy_2}{dx_2} = 2x_2 + 3\). On peut aussi regrouper sous forme vectorielle, telle que \(\frac{dy}{dx} = [\frac{dy_1}{dx_1}, \frac{dy_2}{dx_2}] = [2x_1 + 3, 2x_2 + 3]\).
Étape 3 : application de la règle de la chaîne
Pour obtenir les dérivées de z par rapport à x, on applique la règle de la chaîne :
\(\frac{dz}{dx} = [\frac{dz}{dx_1}, \frac{dz}{dx_2}] = \frac{dz}{dy} * \frac{dy}{dx}\) et \(\frac{dz}{dx} = [\frac{dz}{dy_1}*\frac{dy_1}{dx_1}, \frac{dz}{dy_2}*\frac{dy_2}{dx_2}] = [1 * (2x_1 + 3), 1 * (2x_2 + 3)]\)
et donc \(\frac{dz}{dx} = [2x_1 + 3, 2x_2 + 3]\).
11.5. Résultat numérique pour notre exemple
print(x) # tensor([2., 3.], requires_grad=True)
print(x.grad) # tensor([7., 9.])Car :
- Pour \(x_1 = 2 → \frac{dz}{dx_1} = 2*2 + 3 = 7\)
- Pour \(x_2 = 3 → \frac{dz}{dx_2} = 2*3 + 3 = 9\)
Ainsi, Autograd reproduit automatiquement ce calcul grâce au graphe computationnel et à la règle de la chaîne.
📖 12. Manipuler les tenseurs sans gradients
En PyTorch, il est souvent utile de séparer certaines opérations du calcul des gradients. Voici trois outils pour cela : .detach(), .clone() et torch.no_grad().
12.1. .detach()
- Crée un nouveau tenseur avec les mêmes valeurs que l’original, mais sans suivre le calcul des gradients.
- Utile pour utiliser ou visualiser des valeurs sans affecter la rétropropagation.
x = torch.tensor([1.0, 2.0], requires_grad=True)
y = x * 2
z = y.detach() # z ne calcule pas de gradient
print(z)12.2. .clone()
- Crée une copie indépendante d’un tenseur.
- La copie peut continuer à calculer des gradients si
requires_grad=True. - Utile pour conserver un état avant modification.
y_clone = y.clone()
print(y_clone)12.3. torch.no_grad()
- Contexte qui empêche toutes les opérations à l’intérieur de lui de calculer des gradients.
- Utile pour l'évaluation du modèle, quand on ne veut pas mettre à jour les paramètres du modèle.
- Permet d'économiser de la mémoire et d'accélérer les calculs.
with torch.no_grad():
y_no_grad = x * 2
print(y_no_grad)🍀 Exercice 1 : Calculer le gradient d’une fonction simple avec PyTorch
Considérons la fonction suivante : \(f(a) = a^2 + a\), avec \(a = 1.0\).
Consigne : Utiliser les deux approches suivantes pour calculer le gradient de cette fonction par rapport à \(a\) :
1) Calculez à la main la dérivée de \(f\) par rapport à \(a\). Puis évaluez ce gradient pour \(a = 1.0\).
2) Faites l'implémentation de la même fonction avec PyTorch, calculez et évaluez son gradient.
3) Comparez le résultat obtenu par PyTorch avec le calcul manuel.
Astuce :
La dérivée de \(f(a)\) par rapport à \(a\) est égale à \(2a + 1\)
Résultat attendu : Le gradient est égal à 3 dans les deux cas.