Chapitre 7 - Hyperparamètres: Contrôler et optimiser son entraînement
🎯 Objectifs du Chapitre
À la fin de ce chapitre, vous saurez définir et utiliser les concepts suivants pour contrôler et optimiser l'entraînement de vos modèles de Deep Learning :
L'entraînement d'un réseau de neurones dépend fortement des hyper-paramètres, ces valeurs fixées avant l'entraînement et qui influencent profondément la performance, la stabilité et la vitesse de convergence du modèle. Contrairement aux paramètres appris automatiquement (poids et biais), les hyper-paramètres requièrent une maîtrise conceptuelle et une expérimentation réfléchie.
Dans ce cours, nous examinerons quatre leviers essentiels pour optimiser un entraînement :
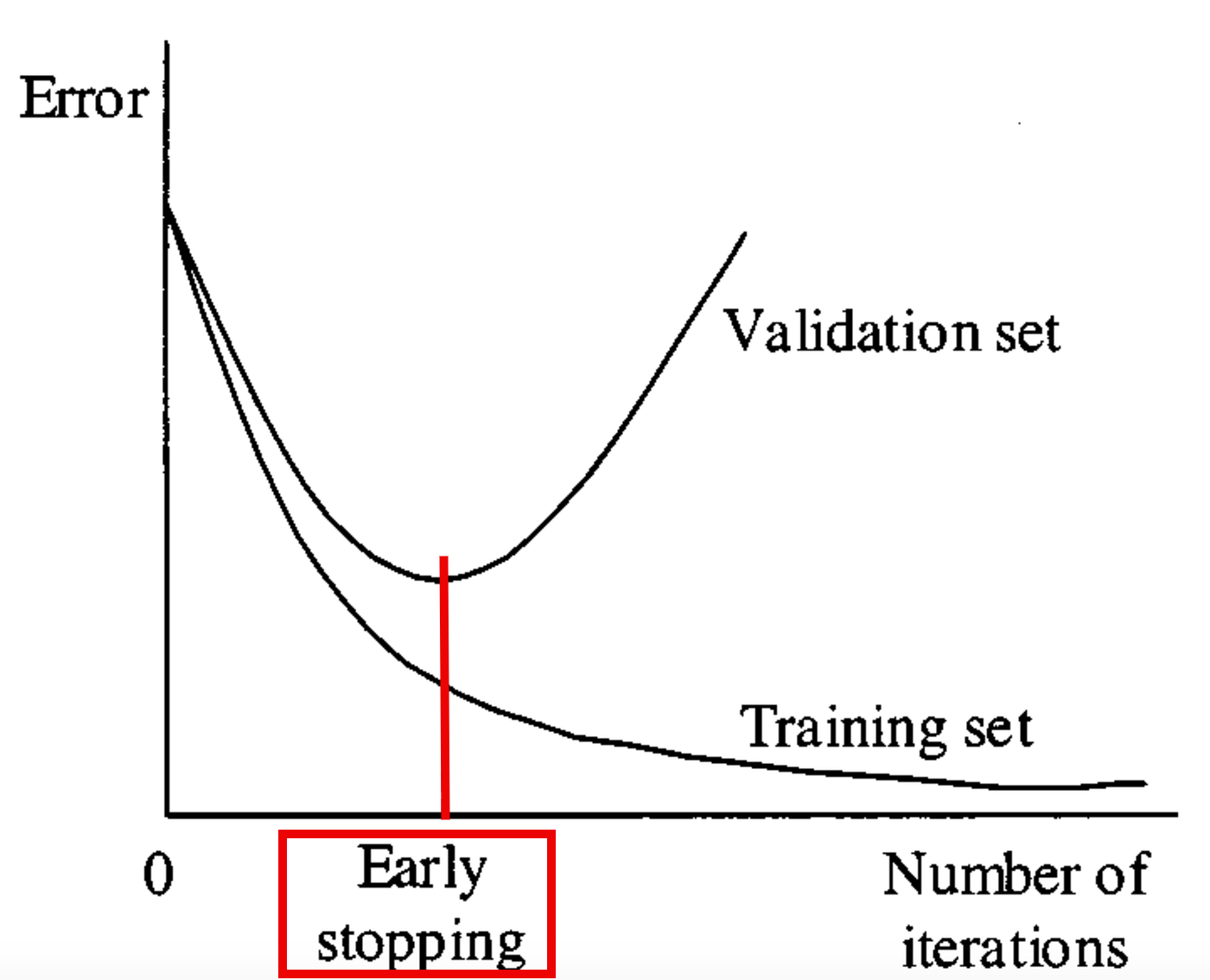
L'early stopping consiste à arrêter l'entraînement lorsque les performances sur le jeu de validation cessent de s'améliorer. Il s'agit d'un moyen simple et efficace d'éviter l'overfitting.
Par exemple, lorsque l'on ne sait pas combien d'époques un modèle doit être entraîné, il est commun de fixer le nombre d'époques à une valeur élevée (e.g., 2000). L'early stopping permet d'arrêter l'entraînement pour éviter du surapprentissage et économiser les ressources de calcul (notamment GPU).
Objectifs
Comprendre comment détecter le surapprentissage (overfitting) pendant l'entraînement.
Savoir interrompre l'entraînement au bon moment pour optimiser la généralisation.
Utiliser un mécanisme automatique d'arrêt avec une « patience ».
Figure 1 : Early Stopping - Arrêt de l'entraînement lorsque la performance sur le jeu de validation se dégrade.
Exemple de code dans la boucle d'entraînement qui utilise l'Early Stopping :
import torch
import numpy as np
patience = 10
patience_cpt = 0
patience_improvement = 0.001 # "Quantité" minimale d'amélioration de la loss pour considérer qu'il y a eu une amélioration
best_val_loss = np.inf
for epoch in range(2000):
train(...)
val_loss = validate(...)
# Il y a amélioration : on réinitialise le compteur de patience et on sauvegarde le modèle
if val_loss < best_val_loss - patience_improvement:
best_val_loss = val_loss
patience_cpt = 0
torch.save(model.state_dict(), "best_model.pt")
# Il n'y a pas d'amélioration : on incrémente le compteur de patience
else:
patience_cpt += 1
# La patience est épuisée : on arrête l'entraînement
if patience_cpt >= patience:
print("Early stopping at epoch", epoch)
break
model.load_state_dict(torch.load("best_model.pt"))
⚠️ Le suivi de l'Early Stopping se fait sur le jeu de validation !
Ne jamais utiliser le jeu de test pour décider d'arrêter l'entraînement, car cela biaiserait l'évaluation finale du modèle.
📖 2. Learning Rate Scheduler
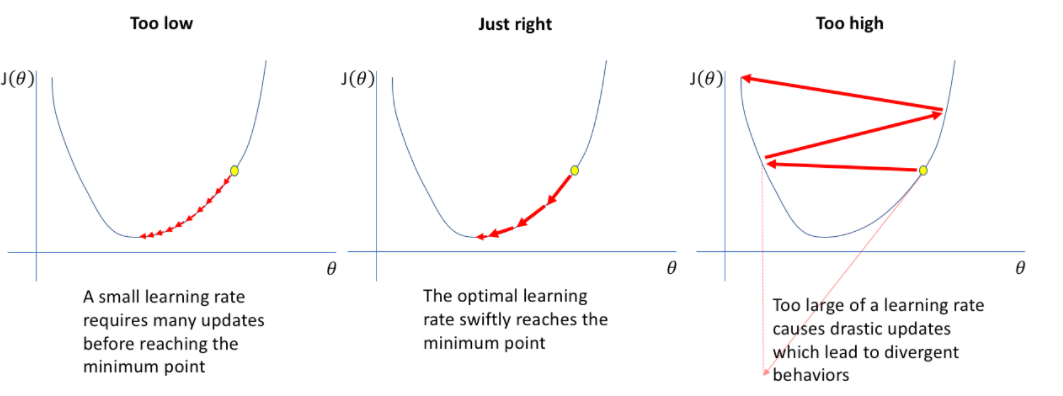
Le learning rate (pas d'apprentissage en français) influence directement la vitesse et la stabilité de la convergence. Un scheduler modifie automatiquement sa valeur selon une stratégie.
🧠 Rappel: Le learning rate est un hyper-paramètre crucial qui détermine la taille des pas effectués lors de la mise à jour des poids du modèle pendant l'entraînement. Un learning rate trop élevé peut entraîner une divergence, tandis qu'un learning rate trop faible peut ralentir la convergence.
C'est la norme (i.e., longueur) du vecteur de mise à jour des poids.
Figure 2 : SGD - Illustration de la mise à jour des poids avec un learning rate trop petit (gauche), trop grand (droite) et ajusté dynamiquement (centre). La valeur du learning rate influence la norme du vecteur gradient.
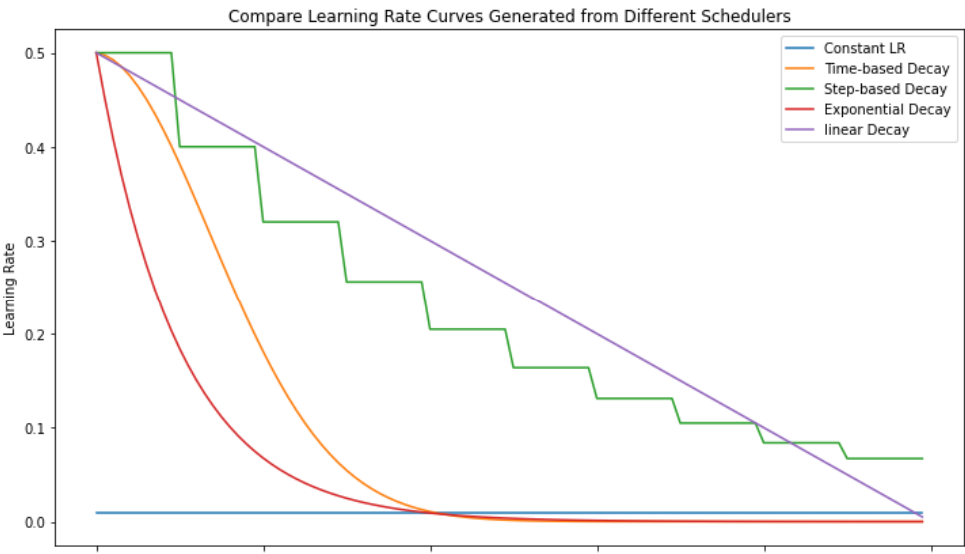
Réduire le Learning Rate au cours de l'entraînement permet souvent d'améliorer la convergence et la performance finale du modèle. Plusieurs stratégies existent, telles que la réduction par palier, la réduction exponentielle, ou les méthodes basées sur la performance (e.g., ReduceLROnPlateau).
PyTorch propose plusieurs classes de scheduler dans le module torch.optim.lr_scheduler. Ces classes prennent nécessairement un optimiseur en argument lors de leur initialisation.
Une fois déclaré, utiliser le scheduler dans la boucle d'entraînement consiste à appeler la méthode step() à chaque époque (ou selon une autre fréquence, selon le scheduler).
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
# StepLR -- Réduction à intervalles fixes
step_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# ReduceLROnPlateau -- Réduction basée sur la performance (patience)
plateau_scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, factor=0.5, patience=3
)
# ExponentialLR -- Réduction exponentielle
exp_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)
# CosineAnnealingLR -- Réduction basée sur le temps, suivant une loi cosinusoïdale
cosine_time_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)
# LinearLR -- Réduction linéaire
linear_scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=1.0, end_factor=0.1, total_iters=100)
# Utilisation du scheduler dans la boucle d'entraînement
for epoch in range(50):
train_loss = train(...)
val_loss = validate(...)
scheduler.step(val_loss) # Pour ReduceLROnPlateau, on passe aussi la métrique de validation
Voici une illustration du comportement de ces différentes stratégies au cours de l'entraînement :
Figure 3 : Stratégies de Learning Rate Scheduling - Illustration des différentes stratégies de réduction du learning rate au cours de l'entraînement.
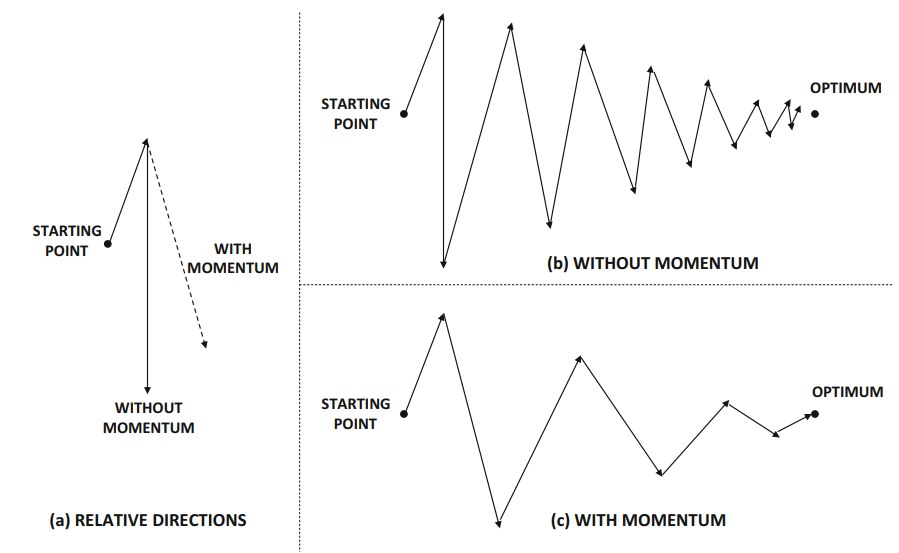
Bonus : Momentum
Le momentum est une technique complémentaire qui aide à accélérer la convergence en accumulant une "vitesse" dans la direction des gradients. C'est une inertie (ou élan) qui permet de lisser les mises à jour des poids en fonction des gradients précédents. Tous les optimiseurs basés sur le gradient (e.g., SGD) peuvent intégrer le momentum.
Figure 4 : Effet du Momentum - Illustration de la mise à jour des poids avec et sans momentum.
⚠️ Il est important de faire attention aux valeurs des gradients lorsque l'on utilise à la fois un optimiseur avec momentum et un Learning Rate Scheduler. Bien que cela soit la plupart du temps efficace, cela multiplie les sources de variations dans les mises à jour des poids, ce qui peut parfois déstabiliser l'entraînement.
📖 3. Regularizers
Les Regularizers (régularisateurs en français)1 pénalisent la complexité du modèle en ajoutant une contrainte aux poids. Ils aident à prévenir l'overfitting en limitant la capacité du modèle à s'adapter trop étroitement aux données d'entraînement.
Les régularisations les plus courantes sont :
L2 Regularization (Ridge) : pénalise la somme des carrés des poids, encourageant des poids plus petits et répartis.
L1 Regularization (Lasso) : pénalise la somme des valeurs absolues des poids, favorisant la sparsité (beaucoup de poids deviennent exactement zéro).
Dropout : technique qui consiste à "éteindre" aléatoirement certains neurones pendant l'entraînement, ce qui aide à prévenir la co-adaptation des neurones et améliore la généralisation.
3.1. L2 Regularization
La régularisation L2 ajoute une pénalité proportionnelle à la somme des carrés des poids du modèle dans la fonction de perte. La formule est donnée par :
\(L_{total}\) est la nouvelle fonction de perte avec régularisation.
\(L_{original}\) est la fonction de perte originale (e.g., erreur quadratique moyenne, entropie croisée, etc.).
\(\lambda\) est le coefficient de régularisation (hyper-paramètre à ajuster).
\(w_i\) représente les poids du modèle.
Cette régularisation encourage les poids à être petits, ce qui réduit la complexité du modèle et aide à prévenir l'overfitting.
En PyTorch, la régularisation L2 peut être facilement appliquée en utilisant le paramètre weight_decay (correspondant à \(\lambda\) dans la formule ci-dessus.) lors de la création de l'optimiseur :
La régularisation L1 ajoute une pénalité proportionnelle à la somme des valeurs absolues des poids du modèle dans la fonction de perte. La formule est donnée par :
\(L_{total}\) est la nouvelle fonction de perte avec régularisation.
\(L_{original}\) est la fonction de perte originale (e.g., erreur quadratique moyenne, entropie croisée, etc.).
\(\lambda\) est le coefficient de régularisation (hyper-paramètre à ajuster).
\(w_i\) représente les poids du modèle.
Cette régularisation encourage les poids à valoir 0, ce qui favorise la sparsité dans le modèle. Cela peut être utile pour sélectionner automatiquement les caractéristiques les plus importantes dans les données.
Contrairement à la régularisation L2, PyTorch ne propose pas de paramètre weight_decay pour la régularisation L1. Il est donc nécessaire de l'implémenter manuellement comme montré ci-dessous :
l1_lambda = 0.001
for epoch in range(epochs):
optimizer.zero_grad()
output = model(input)
loss = criterion(output, target)
# Ajout de la régularisation L1
l1_norm = sum(p.abs().sum() for p in model.parameters())
loss = loss + l1_lambda * l1_norm
loss.backward()
optimizer.step()
🧠 Pour récapituler.
L1 Regularization :
Pénalise la somme des valeurs absolues des poids.
Encourage la sparsité, c'est-à-dire que de nombreux poids deviennent exactement égaux à zéro.
Utile lorsque vous souhaitez obtenir un modèle économe ou effectuer une sélection automatique des caractéristiques.
L2 Regularization :
Pénalise la somme des carrés des poids.
Encourage des poids plus petits et répartis, mais rarement égaux à zéro.
Utile pour réduire la complexité du modèle tout en conservant toutes les caractéristiques.
Quand utiliser l'une ou l'autre ?
L1 Regularization :
Lorsque vous travaillez avec des données comportant de nombreuses caractéristiques inutiles ou redondantes.
Lorsque vous souhaitez interpréter le modèle en identifiant les caractéristiques les plus importantes.
L2 Regularization :
Lorsque vous souhaitez éviter l'overfitting tout en conservant toutes les caractéristiques.
Lorsque vous travaillez avec des modèles où la sparsité n'est pas une priorité.
Les deux approches peuvent bien entendu être combinées pour bénéficier de leurs avantages respectifs.
3.3. Dropout
Le Dropout (dilution en français) est une technique de régularisation qui consiste à "éteindre" aléatoirement un pourcentage de neurones dans un réseau pendant l'entraînement. Cela empêche les neurones de co-adapter leurs poids, ce qui améliore la généralisation du modèle.
Le dropout est généralement appliqué après une couche d'activation (e.g., ReLU) et avant la couche suivante.
Cette technique n'est utilisée que pendant l'entraînement. Lors de l'inférence (évaluation), tous les neurones sont actifs.
\(y_i\) est la sortie du neurone après application du dropout.
\(z_i\) est la sortie initiale du neurone avant dropout.
\(p\) est la probabilité de diluer (i.e., ignorer) un neurone (hyper-paramètre à ajuster).
⚠️ Ici c'est bien la sortie du neurone (feature map) qui est diluée, et non la valeur des poids.
En démontrera l'implémentation où le Dropout est appliquée sur les caractéristiques (features) des données.
En un sens, on peut considérer le Dropout comme une augmentation de données qui "bruite" les activations internes du réseau pendant l'entraînement, forçant le modèle à apprendre des représentations plus robustes.
En PyTorch, le Dropout peut être facilement appliqué comme une couche en utilisant la classe nn.Dropout. Voici un exemple d'utilisation :
import torch
import torch.nn as nn
class My_Network(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 512)
self.drop = nn.Dropout(0.5) # Couche de Dropout avec une proba p=0.5 de dilution
self.fc2 = nn.Linear(512, 10)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.drop(x) # Application du Dropout **uniquement pendant l'entraînement** (model.train())
return self.fc2(x)
Comme on peut le voir dans le code ci-dessus, la couche de Dropout est appliquée sur les caractéristiques (features) des données x = self.drop(x).
Cette couche se désactive automatiquement lors de l'évaluation du modèle (i.e., mode évaluation avec model.eval()).
📖 4. Normalizers
4.1. Problème de distribution
Les réseaux de neurones sont des machines statistiques sensibles aux distributions des données, à leur domaine de valeur. On peut définir deux types de distributions de données :
In-distribution (ID) : données qui suivent la distribution que le modèle a l'habitude de voir et est capable de traiter efficacement.
Out-of-distribution (OOD) : données qui suivent une distribution que le modèle n'a jamais vu et qu'il ne traite donc pas efficacement.
Cette distinction ID/OOD est vraie pour les domaines de valeur mais également pour la distribution globale des caractéristiques d'une donnée.
Par exemple : Soit un réseau entraîné à classer des chiens et chats sur des images dont les canaux RGB sont normalisés entre 0 et 1.
Si on lui présente une image de chien avec des canaux RGB entre 0 et 1, l'image est in-distribution (ID).
Si on lui présente une image de chien avec des canaux RGB entre 0 et 255, l'image est out-of-distribution (OOD) car le modèle n'a jamais vu ce type de données.
Si on lui présente une image d'oiseau avec des canaux RGB entre 0 et 1, l'image est également out-of-distribution (OOD) car le modèle n'a jamais vu ce type de données.
Avec les normalizers, nous allons nous intéresser au domaine de valeur des caractéristiques internes (i.e., sorties des couches intermédiaires) d'un réseau de neurones (normaliser le cas 2. ci-dessus).
Pourtant, il est normal que les distributions des caractéristiques internes (i.e., sorties des couches intermédiaires) varient au cours de l'entraînement puisqu'elles sont dépendantes des poids qui sont mis à jour à chaque itération. Ce changement de distribution interne est appelé le internal covariate shift (décalage interne des covariables en français) et peut ralentir l'entraînement.
4.2. Normalizers pour contrer l'internal covariate shift
Les Normalizers (normalisateurs en français) sont des techniques utilisées pour standardiser ou normaliser les activations des couches intermédiaires d'un réseau de neurones, et contrebalancent donc l'internal covariate shift.
Pour normaliser ces distributions internes, la plupart des Normalizers se basent sur la même formule :
\(x\) est la valeur d'entrée (activation de la couche intermédiaire).
\(\mu(x)\) est la moyenne des activations.
\(\sigma(x)\) est l'écart-type des activations.
\(\epsilon\) est une petite constante pour éviter la division par zéro.
\(\gamma\) et \(\beta\) sont des paramètres appris qui permettent de redimensionner et de recentrer les activations normalisées. Le modèle a donc une capacité de décrire le domaine de valeur qu'il est capable de traiter.
Différents Normalizers se distinguent par la manière dont ils calculent \(\mu\) et \(\sigma\), ainsi que par le moment où ils sont appliqués dans le réseau.
Les normalizers les plus courants sont :
Batch Normalization (BatchNorm) : normalise les activations en utilisant la moyenne et l'écart-type calculés sur un mini-batch de données. Cela aide à stabiliser et accélérer l'entraînement.
Layer Normalization (LayerNorm) : normalise les activations en utilisant la moyenne et l'écart-type calculés sur toutes les caractéristiques d'une seule donnée. Utile pour les architectures récurrentes, souvent utilisé en natural language processing.
Instance Normalization (InstanceNorm) : normalise les activations en utilisant la moyenne et l'écart-type calculés sur chaque canal d'une seule donnée. Souvent utilisé en computer vision.
Group Normalization (GroupNorm) : divise les canaux en groupes et normalise les activations au sein de chaque groupe. Utile lorsque la taille du batch est petite.
En PyTorch, ces normalizers sont disponibles dans le module torch.nn. Voici un exemple d'utilisation de la Batch Normalization :
import torch
import torch.nn as nn
class ImageNormalizerNetwork(nn.Module):
def __init__(self):
super().__init__()
self.batch_norm = nn.BatchNorm2d(3) # Normalisation des 3 canaux sur tout le batch
self.layer_norm = nn.LayerNorm([3, 224, 224]) # Normalisation pour chaque échantillon du batch (tous les canaux)
self.instance_norm = nn.InstanceNorm2d(3) # Normalisation pour chaque canal de chaque échantillon
self.group_norm = nn.GroupNorm(1, 3) # Normalisation de groupe (1 groupe pour 3 canaux)
def forward(self, x):
x_batch_norm = self.batch_norm(x) # Apply Batch Normalization
x_layer_norm = self.layer_norm(x) # Apply Layer Normalization
x_instance_norm = self.instance_norm(x) # Apply Instance Normalization
x_group_norm = self.group_norm(x) # Apply Group Normalization
return x_batch_norm, x_layer_norm, x_instance_norm, x_group_norm
📖 5. Hyperparameter search/tuning
5.1. La jungle des hyper-paramètres
Tous ce que nous avons vu jusqu'à présent concerne des hyper-paramètres : early stopping (patience), learning rate scheduling (type de scheduler, paramètres), regularizers (type, coefficients), normalizers (type, paramètres).
A cela s'ajoutent d'autres hyper-paramètres importants comme : le choix de l'optimiseur, le learning rate initial, la taille du batch, l'architecture du modèle (nombre de couches, nombre de neurones par couche, activations), etc.
Parmi tous ces choix se cache théoriquement au moins une combinaison optimale qui maximise les performances du modèle sur un jeu de données donné. Cependant, trouver cette combinaison optimale est un défi majeur en Deep Learning.
L'hyperparameter search/tuning (recherche d'hyper-paramètres en français) est le processus d'optimisation des hyper-paramètres d'un modèle de Deep Learning pour améliorer ses performances. Contrairement aux paramètres appris automatiquement (poids et biais), les hyper-paramètres sont fixés avant l'entraînement et influencent profondément la performance, la stabilité et la vitesse de convergence du modèle.
Ce processus est également chronophage étant donné qu'il faut éviter de tester la variation de différents hyper-paramètres sur un entraînement, au risque de ne pas savoir quel hyper-paramètre a réellement eu un impact sur la performance. Il faudrait donc lancer autant d'entraînement qu'il y a de combinaisons d'hyper-paramètres à tester.
5.2. Les stratégies de recherche d'hyper-paramètres
La première approche pour trouver les meilleurs hyper-paramètres est la recherche manuelle, où l'on ajuste les hyper-paramètres en fonction de l'expérience et de l'intuition. Cependant, cette méthode peut être inefficace et sujette à des biais.
⚠️ Attention à bien sauvegarder soi-même les versions testées et les performances obtenues, car les frameworks de Deep Learning ne le font pas automatiquement pour vous.
Des méthodes plus systématiques incluent :
Grid Search : exploration exhaustive d'une grille prédéfinie d'hyper-paramètres. Bien que cette méthode soit simple, elle peut être très coûteuse en temps de calcul.
Random Search : sélection aléatoire d'hyper-paramètres dans des plages définies. Cette méthode est souvent plus efficace que la recherche en grille, surtout lorsque certains hyper-paramètres ont plus d'impact que d'autres.
Bayesian Optimization : utilise des modèles probabilistes pour modéliser la fonction de performance en fonction des hyper-paramètres et guide la recherche vers les régions prometteuses de l'espace des hyper-paramètres.
Hyperband : combine la recherche aléatoire avec une stratégie d'arrêt précoce pour allouer efficacement les ressources de calcul aux configurations d'hyper-paramètres les plus prometteuses.
5.3. Exemples d'implémentation
Certaines librairies proposent directement des outils pour automatiser la recherche d'hyper-paramètres, comme scikit-learn avec sklearn.model_selection.GridSearchCV et sklearn.model_selection.RandomizedSearchCV.
Malheureusement, ces outils sont limités aux modèles implémentés dans scikit-learn et ne sont pas adaptés aux modèles de Deep Learning plus complexes.
D'autres librairies plus spécialisées existent pour le Deep Learning et offrent des fonctionnalités avancées pour la recherche d'hyper-paramètres, telles que :
Optuna
Hyperopt
Ray Tune
Scikit-Optimize
Évidement, il est aussi possible d'implémenter soi-même des stratégies de recherche d'hyper-paramètres en utilisant des boucles et des fonctions d'évaluation personnalisées.
Par exemple, une implémentation de Grid Search peut être réalisée en Python en combinant des boucles imbriquées et des fonctions d'entraînement/évaluation :
D'une manière générale, la recherche d'hyper-paramètres commence par définir un espace de recherche (i.e., liste ou plage de valeurs pour chaque hyper-paramètre à tester) et une fonction objective qui entraîne et évalue le modèle pour une combinaison donnée d'hyper-paramètres.
Les différentes stratégies de recherche explorent cet espace de manière plus ou moins efficace pour trouver la combinaison optimale d'hyper-paramètres.
Nous ne présenterons pas ici toutes les librairies existantes pour la recherche d'hyper-paramètres. Chacune à sa propre API et ses spécificités. Cependant, elles partagent toutes le même principe général : un espace de recherche et une fonction objective.
Voici à titre d'exemple une implémentation simple avec la librairie Hyperopt qui utilise l'algorithme TPE (Tree-structured Parzen Estimator) pour optimiser deux hyper-paramètres : le learning rate et le weight decay.
from hyperopt import fmin, tpe, hp, Trials, STATUS_OK
import torch
import torch.nn as nn
import torch.optim as optim
# Définir l'espace de recherche des hyper-paramètres
space = {
'lr': hp.loguniform('lr', -10, -1), # Learning rate entre exp(-10) et exp(-1)
'weight_decay': hp.loguniform('weight_decay', -10, -1) # Weight decay entre exp(-10) et exp(-1)
}
def objective(params):
lr = params['lr']
weight_decay = params['weight_decay']
# Initialiser le modèle, la perte et l'optimiseur
model = My_Network()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=lr, weight_decay=weight_decay)
# Entraîner le modèle (simplifié)
for epoch in range(10):
train_loss = train(model, optimizer, criterion)
val_loss = validate(model, criterion)
return {'loss': val_loss, 'status': STATUS_OK}
trials = Trials()
best = fmin(fn=objective,
space=space,
algo=tpe.suggest,
max_evals=50,
trials=trials)
print("Meilleurs hyper-paramètres :", best)