📖 1. Qu'est-ce qu'une image ?
Une image numérique est une représentation discrète d'une scène visuelle.
Elle est constituée d'une grille de pixels organisés en lignes et en colonnes.
La valeur de chaque pixel détermine la couleur et la luminosité à cet emplacement précis de l'image, et peut être donné dans différents espaces colorimétriques, utilisant un ou plusieurs canaux (channel). Par exemple, une image en niveaux de gris utilise un seul canal, tandis qu'une image en couleur RGB (Red, Green, Blue) utilise trois canaux.
Une image est ainsi représentée par un tableau/tenseur \(H \times W \times C\) où
- \(H\) est la hauteur (nombre de lignes),
- \(W\) est la largeur (nombre de colonnes) et
- \(C\) est le nombre de canaux (1 pour les images en niveaux de gris, 3 pour les images RGB, etc.).
⚠️ En fonction de la bibliothèque que l'on utilise, une image peut se présenter sous la forme channel-first (C, H, W) ou channel-last (H, W, C). Ces deux représentations sont identiques, mais il faut faire attention au format utilisé avant de réaliser des opérations matricielles pour lesquelles l'ordre des dimensions est important !
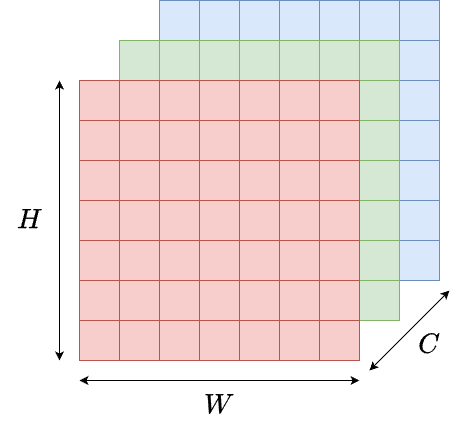
Figure 1 : Exemple de représentation tensorielle d'une image (Hauteur × Largeur × Canaux).
Ainsi, dans une image RGB, chaque pixel a une coordonée (y, x) dans \(H \times W\) qui permet d'accéder à sa couleur encodée par trois valeurs : une pour chaque canal R, G et B. Par exemple, un pixel rouge pur aura les valeurs [255, 0, 0] dans un espace colorimétrique où chaque canal varie de 0 à 255 (i.e., encodé sur 8 bits). En Machine Learning, il est commun de normaliser ces valeurs de [0; 255] vers [0; 1] (en divisant toutes les valeurs par 255).
D'autres espaces de couleurs existent, comme HSL, HSV, CIELAB...
- HSL (Hue, Saturation, Lightness) : HSL décompose la couleur en trois composantes : la teinte (Hue, la couleur pure), la saturation (Saturation, l'intensité de la couleur) et la luminosité (Lightness, la clarté). Cet espace est utile pour des opérations comme le changement de teinte ou l'ajustement de la luminosité, car il correspond mieux à la perception humaine des couleurs.
- HSV (Hue, Saturation, Value) : Similaire à HSL, HSV utilise la teinte, la saturation et la valeur (Value, qui représente la brillance). Il est souvent utilisé en traitement d'image pour la segmentation ou le filtrage de couleurs, car il permet de séparer facilement la couleur pure de son intensité.
- CIELAB (Lab) : L'espace CIELAB est conçu pour être perceptuellement uniforme, c'est-à-dire que la distance entre deux couleurs dans cet espace correspond à la différence perçue par l'œil humain. Il se compose de trois axes : L (luminosité), a (du vert au rouge), et b* (du bleu au jaune). CIELAB est utilisé pour des applications où la fidélité de la couleur et la perception humaine sont importantes, comme la retouche photo ou l'impression.
L'intérêt de ces espaces est de faciliter certaines opérations sur les couleurs (ajustement de la teinte, segmentation, correction de couleur, etc.) qui seraient complexes ou peu intuitives dans l'espace RGB. Selon le problème à traiter, choisir l'espace colorimétrique adapté permet d'obtenir de meilleurs résultats et de simplifier les algorithmes.
Cependant, RGB ainsi que sa variente RGBA (qui contient un canal Alpha supplémentaire pour encoder la transparence) sont les plus utilisés en Machine Learning. Un avantage de RGB est que chaque canal est indépendant des autres, et tous les canaux ont un domaine de valeur identique ([0; 255]).
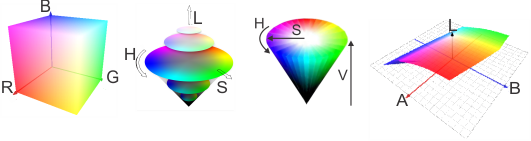
Figure 2 : Espaces de couleur RGB, HSL, HSV et CIELAB.
Une image RGB peut ainsi être découpée en ses trois canaux de couleur individuels (Rouge, Vert, Bleu) en utilisant le slicing :
red_channel = img[:, :, 0] # Canal Rouge
green_channel = img[:, :, 1] # Canal Vert
blue_channel = img[:, :, 2] # Canal Bleu
plt.imshow()
Figure 3 : Séparation des canaux Rouge, Vert et Bleu d'une image RGB.
📖 3. Annotation
L'annotation d'images est une étape cruciale dans la préparation des données pour les tâches de vision par ordinateur en apprentissage supervisé. Elle consiste à ajouter des informations supplémentaires aux images, telles que des étiquettes, des boîtes englobantes, des masques de segmentation, ou des points clés, afin de fournir un contexte et des références pour l'entraînement des modèles.
L'annotation peut être réalisée manuellement par des annotateurs humains ou automatiquement à l'aide d'algorithmes, bien que la qualité et la précision des annotations manuelles soient souvent supérieures.
Les types courants d'annotations incluent :
- Classification : Attribuer une étiquette à l'ensemble de l'image (par exemple, "chien", "chat", "voiture").
- Détection d'objets : Dessiner des boîtes englobantes autour des objets d'intérêt dans l'image et attribuer une étiquette à chaque boîte.
- Segmentation : Créer des masques qui délimitent précisément les objets dans l'image, pixel par pixel.
- Points clés : Marquer des points spécifiques sur les objets, comme les articulations d'un corps humain (détection de plusieurs objets).
L'annotation est essentielle pour entraîner des modèles de vision par ordinateur, car elle fournit les données d'entrée et les cibles nécessaires pour l'apprentissage supervisé. La qualité des annotations a un impact direct sur la performance du modèle, et des annotations incorrectes ou incohérentes peuvent entraîner des résultats médiocres.

Figure 4 : Exemples d'annotations d'images pour différentes tâches de vision par ordinateur - classification, détection d'objets et segmentation.
📖 4. Convolution
Une convolution est une opération mathématique qui applique un filtre (ou noyau, "kernel" en anglais) sur un signal. Appliquer le filtre consiste à faire glisser le noyau sur le signal et à calculer le produit scalaire entre le noyau et la partie du signal qu'il recouvre. En Machine Learning, les convolutions sont principalement utilisées dans les réseaux de neurones convolutifs (CNN pour Convolution Neural Network). Celles-ci permettent de détecter des motifs (contours) et extraire des caractéristiques localement dans l'image (un pixel étant traité avec ses voisins). Ces réseaux sont particulièrement efficaces pour la classification d'images, la détection d'objets et la segmentation d'images.
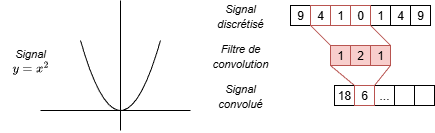
Figure 5 : Exemple de l'application d'un filtre de convolution sur un signal 1D.
Dans l'exemple ci-dessus : soit le noyau \(a = [1, 2, 1]\) aligné avec les valeurs \(b = [4, 1, 0]\) du signal. On applique la formule \( \sum_{i=0}^{N} a_i*b_i\), le résultat est donc : \(4*1 + 1*2 + 0*1 = 6\). Une convolution n'est donc pas plus compliquée qu'une simple somme pondérée.
Padding - Comme on peut le voir dans les figures 5 et 6, la taille du signal convolué est inférieure à celle du signal d'origine. Cela est dû à la manière dont le filtre est appliqué, en glissant sur le signal et en ne produisant une sortie que lorsque le filtre est complètement superposé au signal. Pour compenser cette réduction de taille, il est courant d'utiliser un remplissage (padding) qui ajoute des zéros autour du signal d'origine avant d'appliquer la convolution.
Stride - Le pas (stride) est un autre paramètre important dans la convolution. Il détermine de combien de positions le filtre se déplace à chaque étape. Un stride de 1 signifie que le filtre se déplace d'une position à la fois, tandis qu'un stride de 2 signifie qu'il saute une position entre chaque application. Dans la figure 5, le stride est fixé à 1.
Pour convoluer une image, il suffit de reproduire l'opération en 2D. Le noyau est alors une matrice, le padding peut s'appliquer tout autour de l'image, et le stride est en deux dimensions (pas horizontal et vertical).
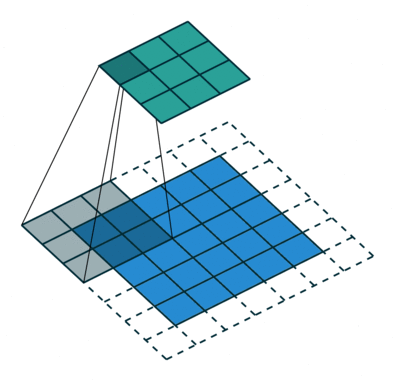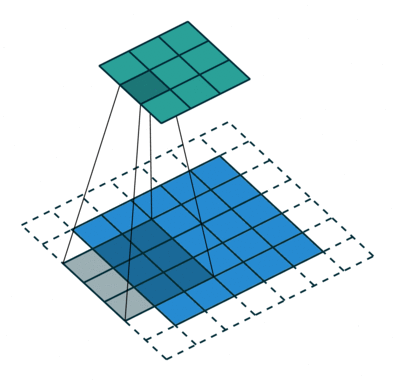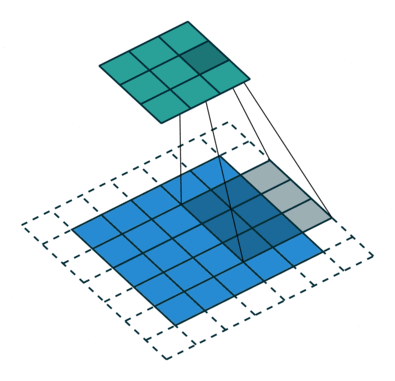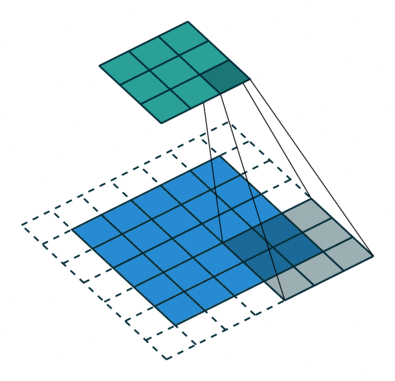
Figure 6 : Exemple de convolution d'une image. L'image est représentée par des carrés bleus. Autour de celle-ci, les carrés en pointillés représente le remplissage (padding), c'est-à-dire l'ajout de pixels fictifs tout autour de l'image, et dont la valeur est nulle. Le filtre de convolution est représenté en gris et superposé à l'image. Celui-ci glisse sur l'image par pas de 2 verticalement et horizontalement (stride=(2,2)). Le signal convolué est représenté en vert.
En résumé, une convolution est déterminée par :
- kernel et kernel_size : Le noyau de convolution (i.e., sa taille et ses valeurs)
- stride : Le pas de l'application du filtre (verticalement et horizontalement)
- padding : Le remplissage appliqué au signal d'origine
La taille du signal convolué est déterminée par celle de l'image d'origine et de ces trois paramètres.
En PyTorch, la convolution 2D est implémentée dans la classe `torch.nn.Conv2d`, qui permet de définir un filtre de convolution avec des paramètres personnalisables. Les valeurs du filtre (noyau) sont initialisées aléatoirement et optimisées lors de l'entraînement du réseau de neurones. L'apprentissage se fait donc au niveau du noyau de convolution, au lieu de le définir manuellement.
Voici un exemple simple d'utilisation de cette classe pour appliquer une convolution à une image :
import torch
import torch.nn as nn
image = torch.randn(1, 3, 64, 64) # 1 image, 3 channels (RGB), 64×64 pixels
# Définir une couche de convolution
conv_layer = nn.Conv2d(in_channels=3, out_channels=8, kernel_size=3, stride=1, padding=1)
# Appliquer la convolution à l'image
output = conv_layer(image)
print("Input shape :", image.shape) # torch.Size([1, 3, 64, 64])
print("Output shape:", output.shape) # torch.Size([1, 8, 64, 64])💡Astuce : Pour traiter efficacement des images en PyTorch, la librairie torchvision propose de nombreuses fonctionnalités utiles, telles que des transformations d'images, des jeux de données prétraités et des modèles pré-entraînés. Vous n'en avez pas forcément besoin pour ce TD, mais n'hésitez pas à l'explorer 😉 !